Apach Lucene 특징

확장 가능한, 고성능 색인
- 현대적인 하드웨어에서 150GB/hour 이상 색인
- 작은 RAM 요구 사항
- 일괄 색인으로 빠른 속도로 증가 색인을 생성
강력하며 정확하고 효율적인 검색 알고리즘
- Ranked searching를 통한 최상의 결과를 먼저 반환
- 강력한 쿼리 유형 : 구문 쿼리, 와일드 카드 쿼리, 근접 쿼리, 범위 쿼리 및 기타
- 모든 필드로 정렬(제목, 저자, 내용 등)
- 다수의 동시 업데이트 및 검색
- 유연한 faceting, 하이라이트, 결과 그룹화
- 벡터 공간 모델 및 Okapi BM25 등의 플러그 순위 모델
크로스 플랫폼 솔루션
- 상업 및 오픈 소스 프로그램에 Lucene을 사용 할 수 있는 아파치 라이선스 하에 오픈 소스 소프트웨어로 사용
- 100 % 순수 자바
- 색인과 호환되는 사용 가능한 다른 프로그래밍 언어로 구현
Apach Solr 특징

Schema
- 색인할 문서의 필드와 그 필드 타입을 쉽게 정의
- Lucene의 Analyzer 사용
- Dynamic Field를 지원
- Copy Field를 사용하여 여러 field를 검색 가능한 단일 field로 묶을 수 있음
- 외부 파일을 통해 금지어 등을 설정할 수 있음
Query
- HTTP 인터페이스로 XML/XSLT, JSON, Python, Ruby 와 같은 응답 format 설정
- 쿼리와 필드 값에 근거한 Faceted Search 제공
- query로 검색 정렬을 정의 가능
- 용이한 검색 score 설정
- query에 특정 field에 대한 가중치 부여 가능
Core
- query handler와 확장 가능한 XML format
- unique key field에 기반하여 중복 문서 탐지
- Caching
- query 결과, 필터, 문서에 대한 캐시 설정
- 사용자 수준에서의 캐시 설정 지원
Replication
- rsync transport를 통해 효과적인 분산 색인
- Admin Interface
- cache, update, query 상태를 알려줌
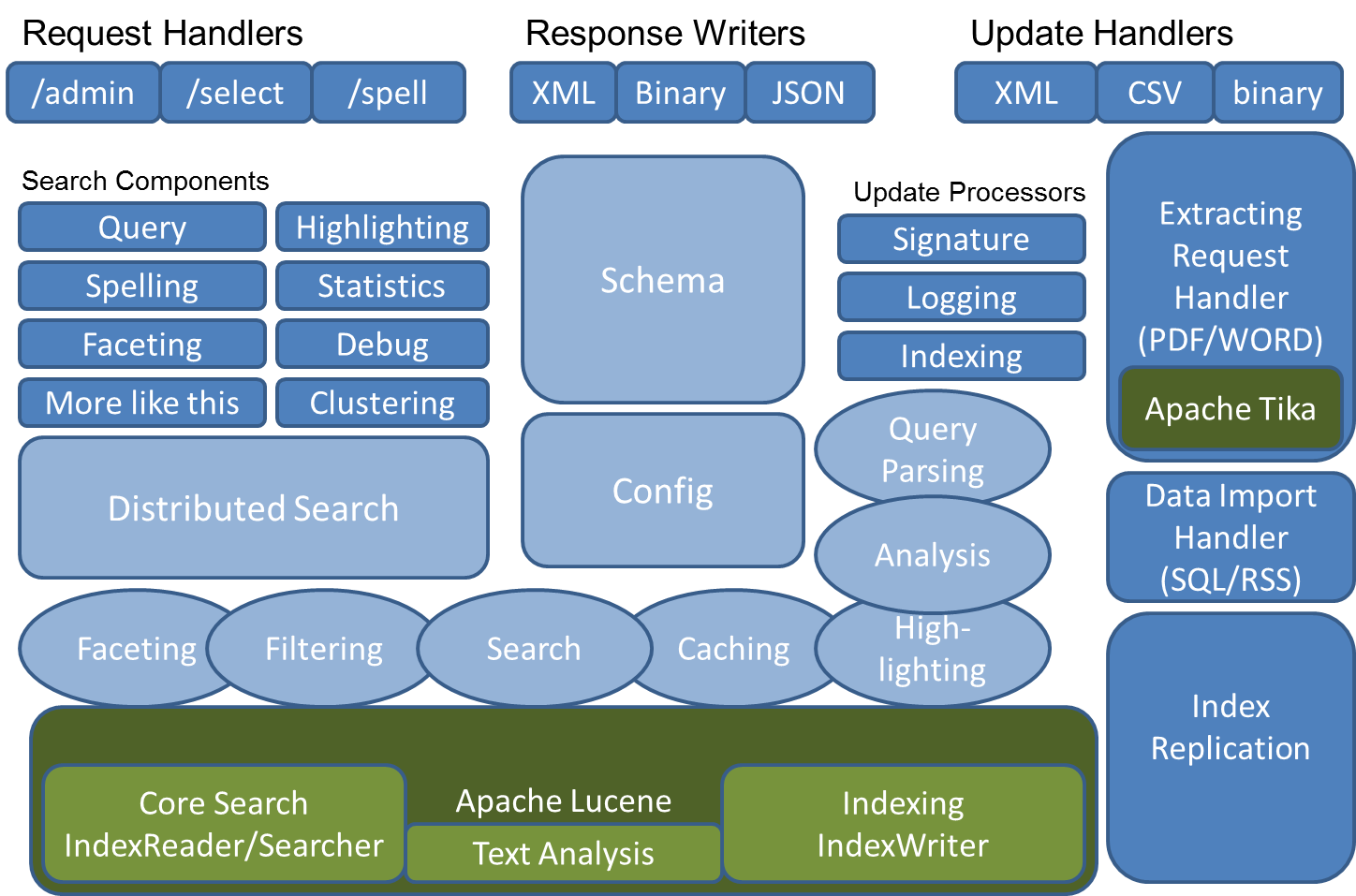
Apach Lucene/Solr 구조